
TL;DR:
- Document indexing organizes and categorizes documents to improve searchability, structure, and accessibility, allowing users to find information efficiently and supporting better decision-making.
- A well-indexed system enhances productivity, reduces file duplication, ensures compliance, and provides a scalable solution to manage increasing data volumes.
- There are several indexing methods—automated, full-text, metadata, tag-based, and hybrid, each suited for different document types and organizational needs.
- Key steps include defining goals, organizing a folder structure, applying metadata consistently, and using indexing software for large document volumes.
Document indexing is the backbone of efficient information management, transforming unstructured content into accessible, searchable, and well-organized data. Even in the digital age, where countless documents are stored online, files can quickly become as disorganized and unmanageable as a cluttered physical archive.
Digitized documents often lack structured organization, creating virtual "piles" of unindexed and uncategorized files. Without a systematic indexing process, these digital documents can be scattered across folders, mislabeled, or saved in formats that make them difficult to search or retrieve. This virtual chaos mirrors the issues that physical archives present—lost information, wasted time, and increased operational inefficiencies.
The chaos also makes it difficult to achieve greater tasks such as document workflow automation. Thus, it's about creating an accessible, searchable, and functional archive that allows users to find what they need and use it for any purpose.
This blog will delve into everything you need to know about document indexing. So, let's jump right in!
What is Document Indexing?
Document indexing organizes and categorizes documents to make them easily searchable and retrievable. It assigns specific labels, tags, or metadata to a document as identifiers. These identifiers allow users to locate the file quickly based on certain keywords or criteria. Indexing can apply to physical and digital documents and is crucial in environments where efficient access to information is needed, such as libraries, corporate records, healthcare systems, and government archives.
Key Components of Document Indexing
- Keywords: Specific words or phrases related to the document's content that make it searchable.
- Metadata: Essential data points, like author name, document date, file type, and subject matter, that describe the document.
- Categories or Taxonomy: Grouping documents into categories (e.g., finance, legal, research) to create a logical structure.
What Purpose Does Document Indexing Serve?
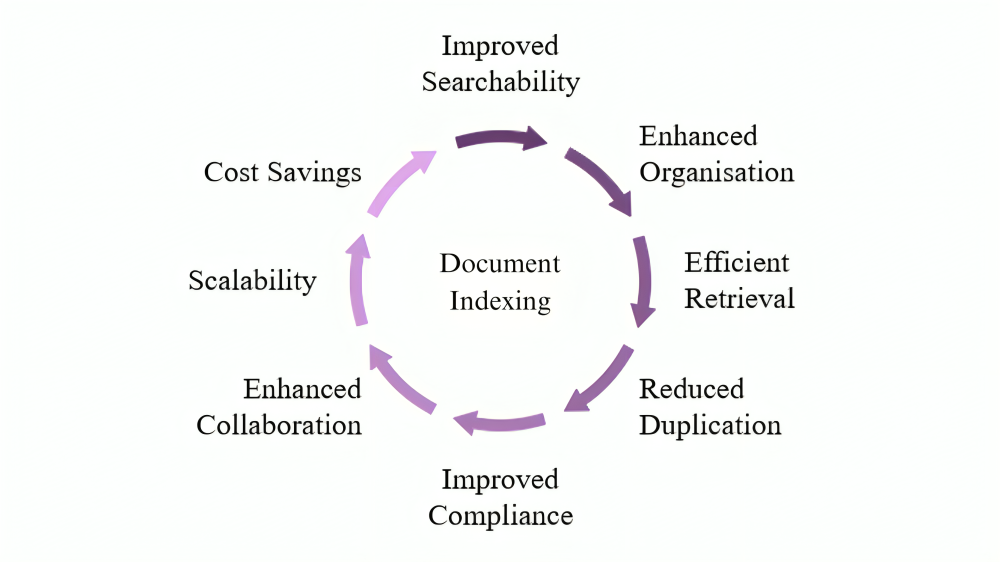
1. Improved Searchability and Quick Access
- Purpose: Indexing lets users quickly locate documents based on keywords, dates, authors, or other relevant metadata.
- Benefit: This means less time spent searching and more time dedicated to productive tasks. This efficiency is particularly valuable in high-paced environments like legal firms, healthcare facilities, and corporate offices.
2. Enhanced Organization and Structure
- Purpose: Indexing establishes a logical structure within document storage systems by creating categories, folders, and tags.
- Benefit: With Indexing, teams can establish a taxonomy that aligns with business needs, making file storage more intuitive and reducing the chance of losing critical information.
3. Efficient Information Retrieval for Better Decision-Making
- Purpose: Indexing supports timely and informed decision-making by creating a systematic way to retrieve information.
- Benefit: In fields where decisions must be made based on the most current or relevant information (e.g., finance, law, research), the ability to retrieve documents quickly can be game-changing.
4. Reduced Duplication and File Redundancy
- Purpose: An effective indexing system can identify duplicate files and reduce unnecessary document duplication.
- Benefit: Indexing helps create a "single source of truth," ensuring everyone has access to the most accurate and updated document version.
5. Improved Compliance and Security
- Purpose: Indexing helps organizations adhere to industry regulations and internal compliance standards by making records easy to track and audit.
- Benefit: A well-indexed document management system can provide controlled access to sensitive data, facilitate audits, and ensure that organizations meet compliance standards without extra work.
6. Enhanced Collaboration and Productivity
- Purpose: Indexing enables team members to access and share documents seamlessly, fostering better collaboration.
- Benefit: Indexing also reduces the need to depend on specific individuals who might know where files are stored, making document access a shared responsibility.
7. Scalability and Future-Proofing
- Purpose: A robust indexing system can grow with an organization, adapting to new documents and data.
- Benefit: Indexing provides a scalable solution that ensures document management systems can keep pace with increasing data without becoming unwieldy or requiring constant restructuring.
8. Cost Savings
- Purpose: By streamlining document management, Indexing reduces direct and indirect costs associated with storing, retrieving, and managing files.
- Benefit: Employees spend less time searching for documents, optimized storage requirements, and minimized errors due to lost or misfiled documents—all contributing to cost savings.
Types of Document Indexing Methods
Document indexing can be approached in several ways depending on the type of documents, the volume of data, and an organization's specific needs.
1. Automated Indexing: It uses software tools to automatically analyze, categorize, and assign metadata to documents. Automated Indexing can rely on pre-defined rules or, in more advanced systems, artificial intelligence (AI) and machine learning (ML) to improve indexing accuracy.
- Use Cases: Ideal for organizations managing large document volumes, such as corporate offices, financial institutions, and healthcare facilities.
- Pros: Fast, scalable, and reduces the need for human intervention; good for handling high volumes.
- Cons: It may lack the contextual accuracy of manual indexing, particularly in nuanced documents.
2. Full-Text Indexing: This method indexes every word within a document, making the entire content searchable. Full-text Indexing relies heavily on search algorithms to make the content accessible by keyword.
- Use Cases: Often used in digital libraries, research databases, and legal repositories where users need the ability to search for any term in a document.
- Pros: Allows for comprehensive search capabilities across entire documents; especially useful for unstructured data.
- Cons: Generates large indexes, which may require significant storage and processing power; can lead to irrelevant search results if not carefully managed.
3. Metadata Indexing: It focuses on indexing documents based on specific metadata attributes, such as title, author, date created, document type, keywords, and subject.
- Use Cases: Commonly used in content management systems (CMS) and digital asset management systems (DAMS) where key document attributes are consistent across records.
- Pros: Smaller and more manageable index size than full-text Indexing; more relevant search results when well-designed.
- Cons: Limited searchability if documents contain valuable information that is not reflected in the metadata.
4. Tag-Based Indexing: It assigns tags to documents based on their content or topic. Tags can be based on themes, categories, or specific keywords related to the document's subject matter.
- Use Cases: Useful for organizing documents within collaborative platforms, content libraries, or digital asset libraries where teams need a flexible way to categorize content.
- Pros: Flexible and user-friendly; easy to implement in collaborative environments.
- Cons: Requires consistent tag usage; prone to inconsistencies if different users tag documents with varying terminology.
5. Hybrid Indexing: It combines multiple indexing methods—such as full-text, metadata, and tag-based indexing—to create a comprehensive and highly effective indexing system.
- Use Cases: Suitable for complex environments with diverse document types and user needs, like large corporations or knowledge management systems.
- Pros: Offers flexibility and increased accuracy by combining different strengths of each method.
- Cons: It can be complex to set up and may require robust systems to manage and maintain.
How to Index Documents?
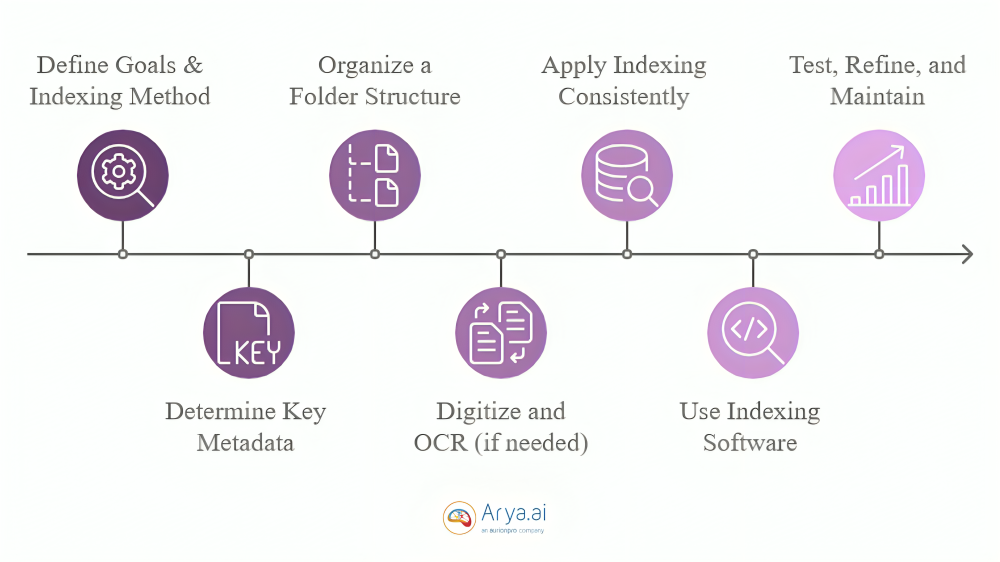
To index documents effectively, follow these key steps:
- Define Goals and Choose an Indexing Method: Identify your purpose for Indexing and choose an appropriate method (e.g., metadata, full-text, or tag-based Indexing).
- Determine Key Metadata: Decide on essential fields such as title, author, date, document type, and relevant keywords.
- Organize a Folder Structure: Create a logical taxonomy or folder structure with broad categories and specific subcategories for easy navigation.
- Digitize and OCR (if needed): Scan physical documents and use Optical Character Recognition (OCR) to make them machine-readable and searchable.
- Apply Indexing Consistently: Enter metadata, tags, and keywords consistently, following standardized terminology to avoid confusion.
- Use Indexing Software: For large repositories, use a Document Management System (DMS) with indexing tools for faster, automated organization.
- Test, Refine, and Maintain: Test the system, refine it based on feedback, and regularly update and remove outdated files to keep the index relevant and efficient.
This process ensures documents are easily searchable, organized, and accessible to improve efficiency and information management.
Challenges in Document Indexing
Document indexing, while essential, comes with several challenges. Inconsistent Tagging and Metadata Standards can lead to confusion and misfiled documents if different users apply inconsistent labels. High Initial Setup Time is also a hurdle, as creating a detailed indexing system requires careful planning and resources. Accuracy Limitations may occur in automated Indexing, particularly with complex or nuanced content where automated systems may misinterpret context.
To overcome challenges in document indexing, consider these solutions:
- Establish Clear Standards: Develop standardized tagging and metadata guidelines to ensure consistency across users and documents.
- Use Automation Wisely: Leverage AI and machine learning for indexing automation, especially for large volumes, and use manual review for accuracy in complex cases.
- Implement Scalable Technology: Choose a document management system (DMS) that supports scalable Indexing to handle growing data volumes.
- Regular Training and Audits: Conduct periodic training sessions and audits to update users on indexing practices and catch inconsistencies early.
- Continuous Refinement: Regularly review and refine indexing strategies as new document types are added or organizational needs change.
Conclusion
A well-designed indexing system transforms vast information stores into easily accessible, organized assets that support faster decision-making, improved compliance, and enhanced productivity. Although maintaining consistency and scaling systems can be daunting, leveraging modern technologies and well-defined standards can turn Indexing into a powerful tool. Investing in better document management solutions allows organizations to manage their documents more effectively to drive better outcomes.
