
Organizations worldwide are achieving impressive results across a wide spectrum of use cases, with Artificial Intelligence and Machine learning systems. Even with multiple use cases already in play, the opportunities with AI are unparalleled and its potential is far from exhausted.
As organizations scale their AI and ML efforts, they are now reaching an impasse - explaining and justifying the decisions by AI models. Also, the formation of various regulatory compliance and accountability systems, legal frameworks and requirements of Ethics and Trustworthiness, mandate making AI systems adhere to transparency and traceability
The tradeoff between accuracy and explainability has always created inhibitions for stakeholders to either adopt for scale AI and ML technologies within their organizations.
This is where Explainable AI (XAI) comes in - to eliminate the tradeoff and make AI explainable, transparent and reliable.
Explaining a model entails explaining all aspects of the model that are:
- Prediction related - how did the engine arrive at the prediction
- Model related - how did the model analyse data and what did it learnt from it
- Data related - how was the data used to train the model
- Influence and controls - what can influence the system and thereby ways to control
Current Methods of XAI in Deep Learning
Since AI explainability is becoming a norm, organizations have begun to move beyond treating these models as ‘blackboxes’, using a multitude of methods available to explain even the complex AI systems.
Today, multiple methods like LIME, SHAP, make it possible to understand these complex systems. The current methods can be broadly categorized into Visualization based methods and Distillation methods.
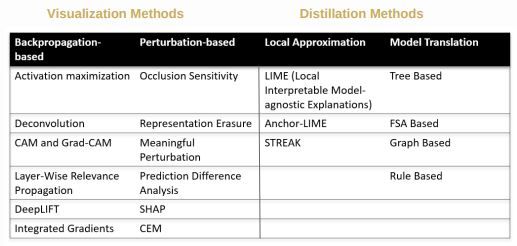
Visualization based methods
1. Backpropagation-based methods:
Backpropagation-based methods highlight parts of your data, which are strongly inferential towards the output. They can either do this by considering the network structure or using different components within the network itself.
Within back-propagation methods where network structures are used, there are methods such as Activation maximization, Deconvolution, Class activation maps (CAM) and Grad-CAM, which utilize either the pooling layers or convolution layers activation function to propagate back which input was responsible for that particular output. So, these methods heavily rely on convolution layers to be present in the network.
Layer wise relevance propagation method uses scalar expansion to propagate relevance from the output towards the input layers. DeepLIFT and Integrated Gradients use a reference sample to calculate the impact based on the change between the samples. DeepLIFT directly takes the differences between different components of the network, and the Integrated Gradients method integrates the gradients along the complete path (from output to input) between the sample and reference to calculate the influence of a particular feature on the output, which can be both positive or negative
2. Perturbation-based methods:
These methods treat the network as a complete black box. They try to remove or alter information to see what are the changes in the network output. Based on those changes, they can either highlight the change that was selecting more, or calculate marginal modular contributions based on each part of the data set. It can be a different feature in case of tabular data, or a word in case of subtext in GIF images, or they can be parts of images or a couple of pixels.
In the Occlusion Sensitivity technique, parts of the ocular sensitivity are removed to understand a network's sensitivity in different regions of the data using small perturbations of the data. Whereas, Representation Erasure is more data agnostic - it can be applied to any kind of data. For example, the technique can be used on textual data to move words, or for tabular data to move one or more features, and in case of image data, to erase parts of images. The eraser can be in any form, and can either use a constant value or average values.
Essentially the input is altered to see how the output is being affected - this requires multiple iterations to get an explanation.
SHAP (SHapley Additive exPlanations) is a game theoretic approach. SHAP considers marginal contribution for every feature. Incase of previous metrics, it is easier to calculate marginal contribution in tree based methods, because the features are in a specific order, and based on that order, different orders can be constructed, or different types of levels can be created within the same sample. This technique also makes it possible to see average values of every node before branching. But this order doesn't exist in deep learning. For a given sample data set, SHAP permutes the values for each feature, to see how much the particular feature is affecting your output, and that marginal contribution will be your estimation for that particular feature
Distillation based methods
Distillation based methods build a white box model in conjunction with your current model. For a trained neural network, distillation methods will build a separate, less complex model to explain what is happening within the network. This happens through two methods - Local approximation and Model translation.
-
Local approximation: These methods use a small range of data, or a small data set, concentrated around some particular score to approximate the behavior of the neural network. And within that range, they explain what should be the reason, or what inputs were more responsible for that particular score. Analogous to Taylor expansion, (which converts any complex, non-linear function into a linear function) local approximation method builds a white box model, although complex, but on a smaller range. LIME (Local Interpretable Model Agnostic Explanations) puts together a surrogate model on a small dataset. It is generally useful for random forests, but can also be used for any particular algorithm.
-
Model translation: These methods use the complete data to try to map the input to the network predictions. The input can be mapped to the predictions with the white box model, and then using the white box model, it is possible to explain how decisions are being made. So in this case, a surrogate model is used instead of the original model to explain results.
In model translation, there can be Tree based models, graphs, or even rule based models. So basically, for a completed neural network, a neural network with large depth, each node can be converted into a rule, and these techniques try to explain how the model works. But this has its own caveats, since a continuous system is being converted into a discrete system
Challenges with existing methods:
Most of the algorithms currently being used provide only a positive or a negative inference for every feature. This does not hold true in case of deep learning, since every node is contributing to each node above it
-
Dependency on network architecture: The above mentioned algorithms are heavily dependent on the component being used. One needs to define the architecture based on the algorithm being used for estimation
-
Output from the algorithms: The outputs from the algorithms require a separate reference sample or sample data set. Ideally, since the model and sample both are present, it is possible to explain how the material sample was being used in such a network. A second set of data or a data sample will not be required to explain the same
-
Independent functioning of algorithms irrespective of data type: There are limitations in the existing methods based on the type of input data being used. Ideally, an algorithm should be able to work with all types of data - digital, image, text, or tabular data, there can also be a mix of all three and the algorithm should be able to handle all of them.
-
Explanation of each part of the network: Current methods do not provide explanation for each part of the network. The contribution of any singular unit to all connected units might not be considered
Providing explanations is only part of the reason why these outcomes are used, the other part is understanding how the neural network is working and what it is seeing, such that improvements can be made accordingly.
Ideally an XAI algorithm should be able to address all the above challenges, explaining how the model works and why the model behaved as it did. If it lacks the ability to explain even one or two key areas, the risk of an inaccurate decision or the lack of controls in the methods will outweigh the benefits.
Demystify inner working of ML models with Arya-xAI
If there is an explanation of each part of the network, each change within the neural network can be quantified - how is it being fine tuned, which parts should be pruned in case an alternate output is needed, which features have less or more influence so as to assign different weights for each of them, and also see if those weights are compliant with the business processes.
Essentially, each neural network is built to predict certain variables in the process. For example, while automating a particular process in financial services, the data will have different ordering of each feature, some more important and some less important than others. Now for the model to make a decision, the same ordering should be reflected to prove that it is able to directly replicate this particular business process.
Arya Arya.ai, we built a new framework ‘Arya-xAI’, to ensure responsible AI can be adapted as part of design. We have introduced a new patent pending approach called ‘Back-trace’ to explain Deep Learning systems. It can generate true to model explanations Local/Global by assessing the model directly instead of approximating it from input and outputs.
Back-trace:
- Decodes ‘true-to-model’ feature weightage and node level weightages for any neural network
- Generates explanations at local level and global level
- Offers contrastive explanations on how the variations of the features can impact the final verdict
- Provides feature importance that's comparable and combinable across the dataset, and provides justifications for prediction accuracy
- Opens up the network and offers node and layer level explanations
- Monitors the model in production and informs about the model drift or data drift
- Provides more advanced controls for Audit/Risk/Quality control teams to ensure that the AI solution adheres to business guidelines
To know more about Arya-xAI, please visit the documentation here.
While ‘intelligence’ is the primary deliverable of AI, ‘Explainability’ has become the fundamental need of a product. We hope this blog provided some insight into current XAI approaches and general challenges associated with them.

